
Xuweiyi Chen
About Me
I am a 2nd year Ph.D. student at the University of Virginia advised by Prof. Zezhou Cheng. I do research in 3D Computer Vision.
Before joining UVA, I have completed master of Computer Science and Engineering at the University of Michigan. I was a member of SLED lab. I obtained my bachelor’s degree in Applied and Computational Mathematics Science at the University of Washington where I worked with Prof. Yunhe feng on Responsible AI.
Research Interests
My research centers on scalable approaches to 3D computer vision, language-grounded robotics, and visual world models. I am broadly interested in how visual foundation models can acquire persistent, dynamic, and geometry-aware world representations from real-world multi-view, video, and 3D data.
I currently focus on two themes:
-
Developing vision-centric 3D/4D foundation models. I study how large-scale visual models can learn spatially grounded representations of static and dynamic environments, with an emphasis on multi-view perception, novel view synthesis, 3D scene understanding, and persistent visual memory.
-
Grounding language concepts in 3D environments and robotic actions. I explore how language can be connected to 3D scenes, object affordances, spatial relations, and embodied actions, enabling agents to reason, navigate, and interact in complex physical environments.
Internships

Summer 2025

Summer 2026
News
- [Apr. 2026] WildRayZer has been selected as Highlight at CVPR 2026.
- [Feb. 2026] One first-author paper has been accepted to CVPR 2026.
- [Jan. 2026] One first-author paper has been accepted to ICLR 2026.
- [Nov. 2025] One first-author paper has been accepted to 3DV 2026.
- [Feb. 2025] Two first-author papers have been accepted to CVPR 2025.
- [Nov. 2024] One first-author paper has been accepted to TMLR.
- [Sep. 2024] One first-author paper has been accepted to NeurIPS 2024.
- [Aug. 2024] Join the University of Virginia advised by Zezhou Cheng.
- [Jan. 2024] Our first-author paper has been accepted by ICRA 2024.
- [Aug. 2022] Joined the SLED lab at the University of Michigan.
First-Author Publications
-
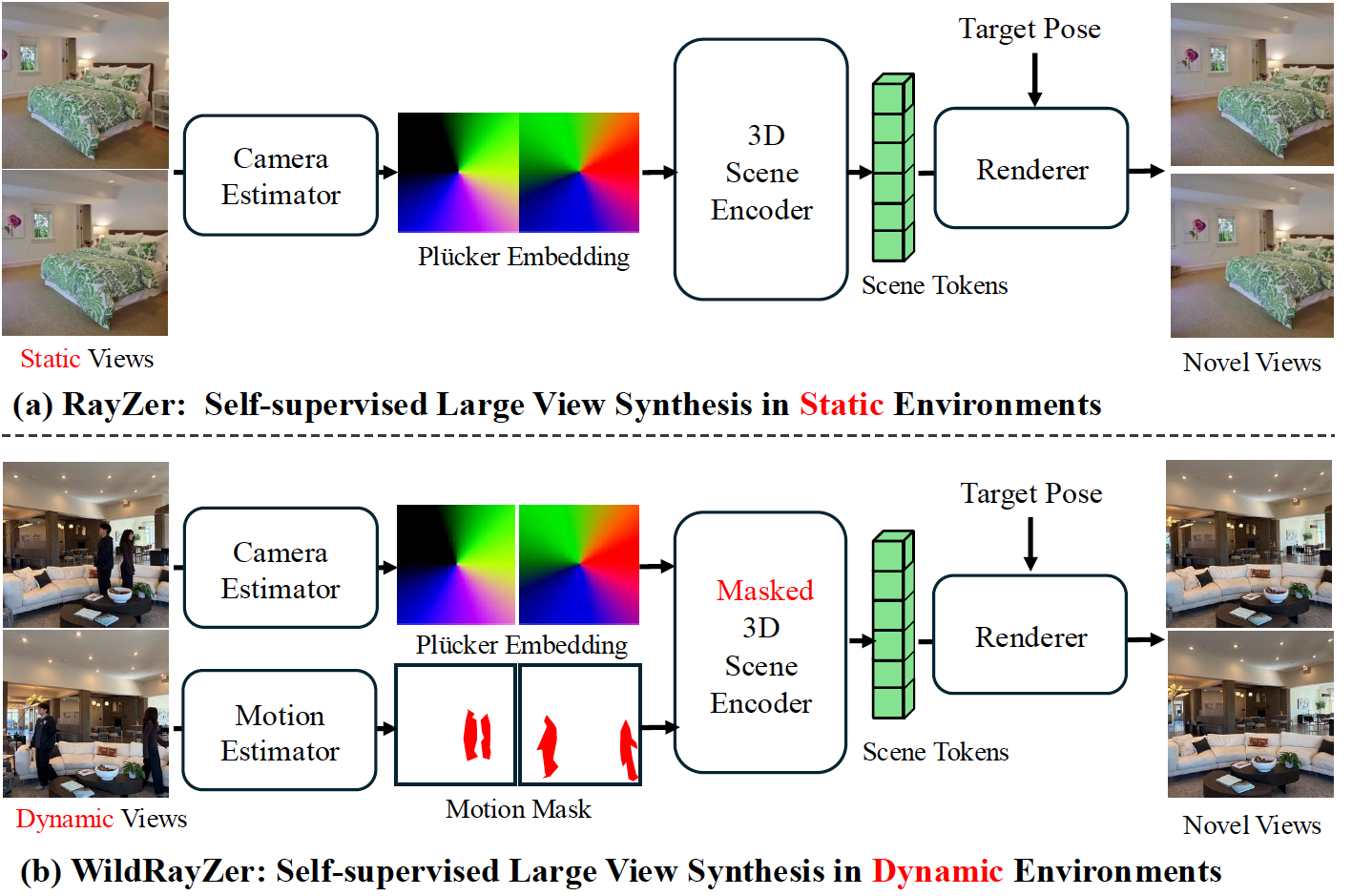 CVPR 2026 (Highlight)
IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026.
CVPR 2026 (Highlight)
IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2026. -
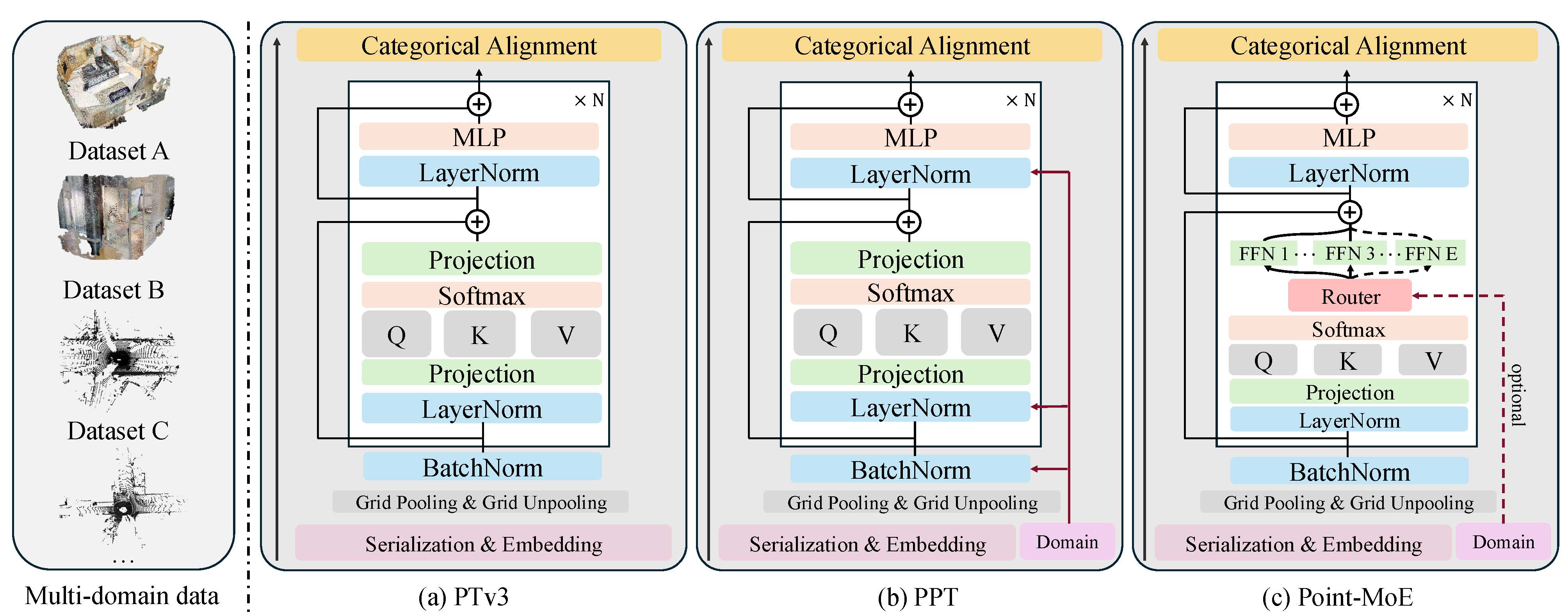 ICLR 2026
International Conference on Learning Representations, 2026.
ICLR 2026
International Conference on Learning Representations, 2026. -
 3D-LLM/VLA @ CVPR 2025
3D-LLM/VLA @ CVPR 2025
-
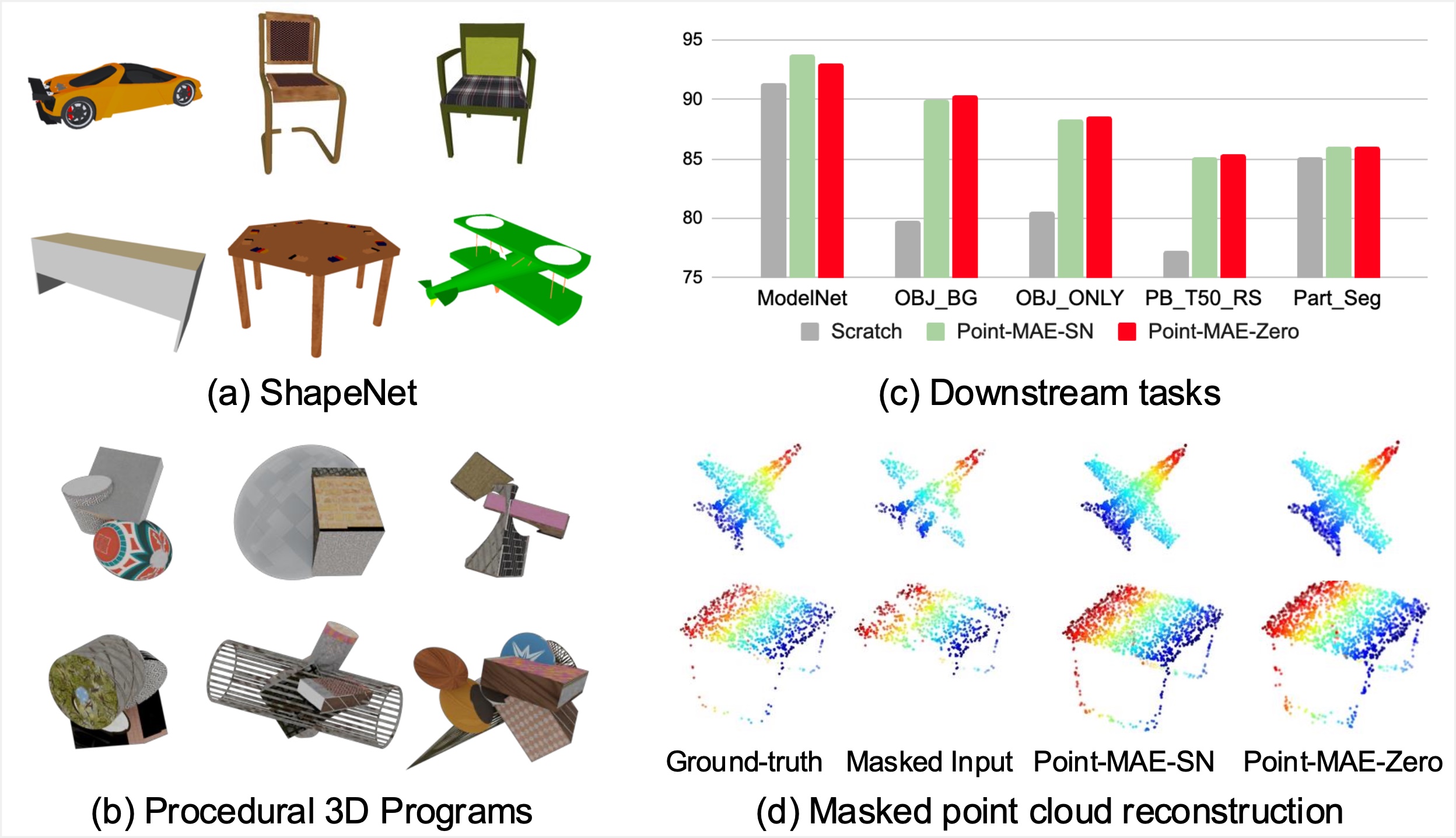 3DV 2026
International Conference on 3D Vision, 2026.
3DV 2026
International Conference on 3D Vision, 2026. -
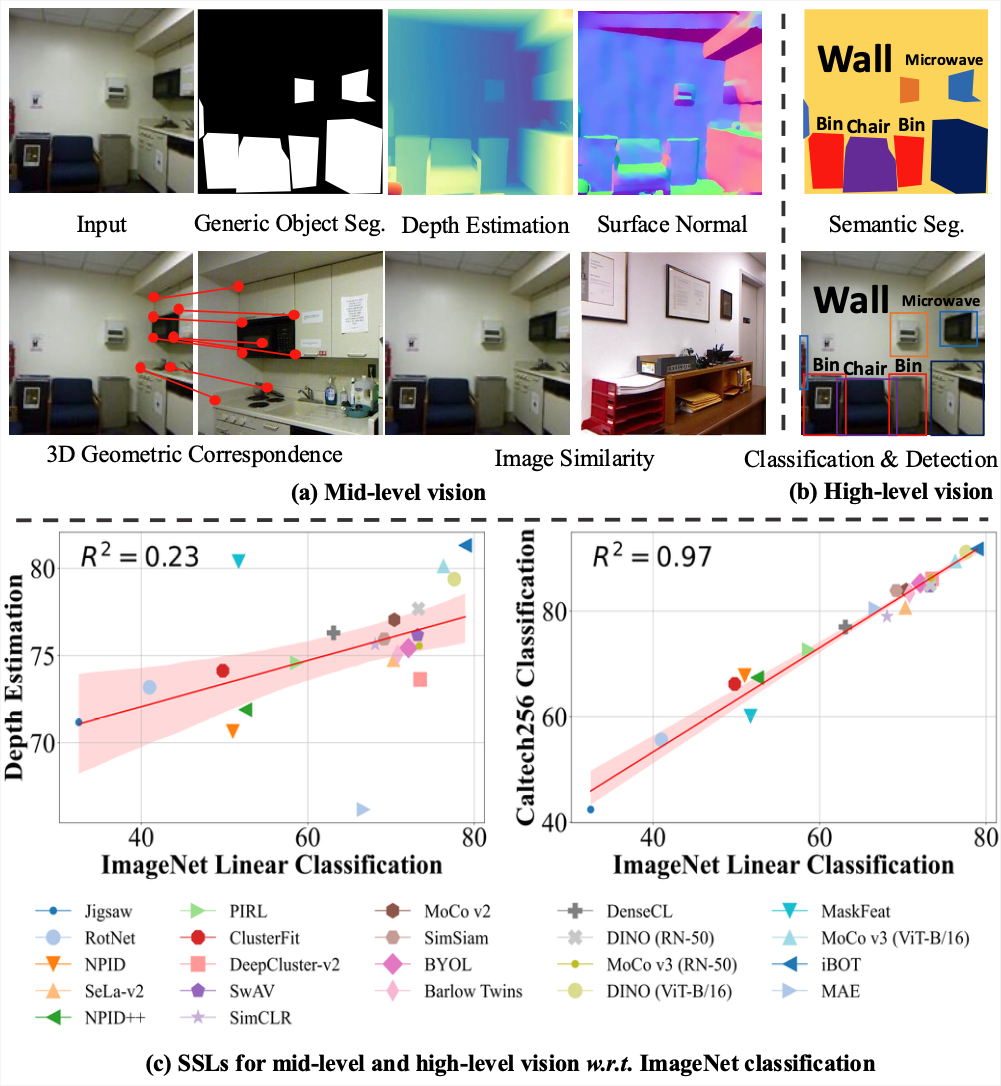 CVPR 2025
IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025.
CVPR 2025
IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. -
 NeurIPS 2024
Conference on Neural Information Processing Systems, 2024.
NeurIPS 2024
Conference on Neural Information Processing Systems, 2024. -
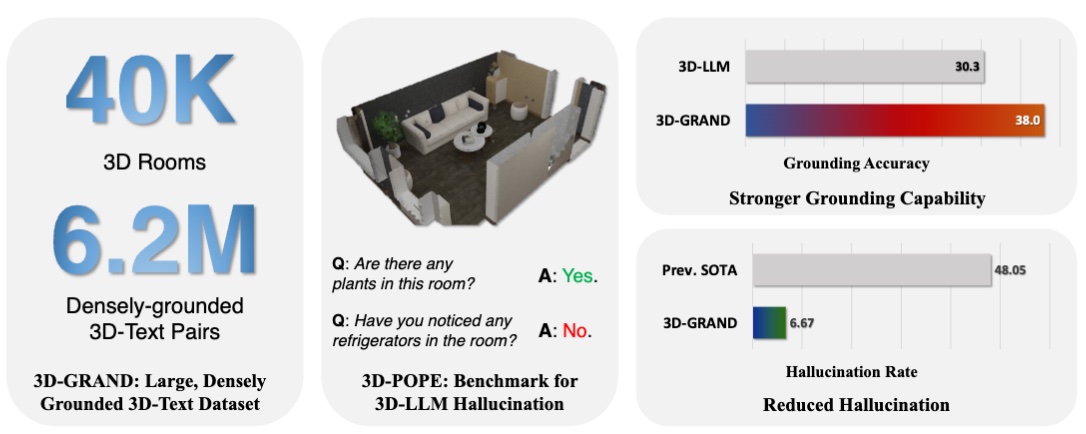 CVPR 2025
IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025.
CVPR 2025
IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2025. -
 TMLR
Transactions on Machine Learning Research.
TMLR
Transactions on Machine Learning Research. -
 ICRA 2024
IEEE Robotics and Automation Society, 2024.
ICRA 2024
IEEE Robotics and Automation Society, 2024.
Conference Reviewers
CVPR 2025 ICLR 2025 European Conference on Computer Vision (ECCV) 2024 IEEE Transactions on Big Data
Powered by Jekyll and Minimal Light theme.